Introduction
The COVID-19 pandemic, amidst its horrors of damage to lives and economies and a complete reshaping of our social interactions, has brought quite a few technical words into our daily lives. Words like modelling, simulation, growth curve, the exponential curve, predictions, projections, curve flattening and so on are being used constantly to usher in new pandemic management policies.
It is in this context that it becomes purposeful to address some of these words so that they can be accessed without much loss of mathematical content and to provide a peek into the essentials of building a model to understand a novel situation. Building a model for an observed event basically implies identifying a mathematical function that best fits the observation and enables meaningful predictions. Essentially this article aims to introduce model building without slipping into a crash course format on statistics.
By the end of this the reader will be familiar with terms like regression, interpolating polynomial and extrapolation. The reader will also be exposed to some of the intricacies and the difficulties that are present while constructing a model. For this purpose, the relevant analysis and presentation of images are constructed on GeoGebra using simple inbuilt tools.
Preliminaries
Consider either a natural phenomenon, be it growth of a bacterial culture or spreading of a pandemic, or planned experiments to determine variation of resistance of a material or even a social event such as poll results that require to be explained. Firstly, it is imperative to identify an independent variable in such a way that the observation does not influence it. For instance, in the case of bacterial growth it could be time or the number of oxygen cylinders needed with respect to the number of Covid-positive cases.
In the case of planned experiments, after identifying the suitable independent variable(s) the experiments are performed to get values of the dependent variable corresponding to various settings of the independent variable. Use of the best available technology over a wide range with fine step size mandates good quality data collection. Sometimes the phenomenon may be rare (e.g. LIGO, Higgs Boson etc.) thus limiting the number of data. Once sufficient data are collected, a relationship in a functional form can be achieved from curve fitting or from modelling. Against this backdrop, let us now try something interesting.
Methods of modelling
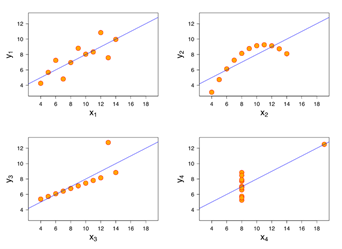
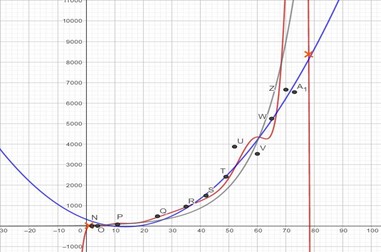
We start with a set of data (points A to G) that have been generated by performing an experiment. Table. 1 presents the observed data and Figure 1 is a scatter plot of the same. Let the various values of the independent variable be denoted by xi and the dependent variable yi. We attempt to model the observed information using a function of the form f(x,bj) where bi are parameters of the function that needs to be determined. In this introductory article we restrict to making models out of polynomial functions.